Master how to work with big data and build machine learning models at scale using Spark! In this course, you’ll learn how to use Spark to work with big data and build machine learning models at scale, including how to wrangle and model massive datasets with PySpark, the Python library for interacting with Spark. In the first lesson, you will learn about big data and how Spark fits into the big data ecosystem. In lesson two, you will be practicing processing and cleaning datasets to get comfortable with Spark’s SQL and dataframe APIs. In the third lesson, you will debug and optimize your Spark code when running on a cluster. In lesson four, you will use Spark’s Machine Learning Library to train machine learning models at scale.
Class Deals by MOOC List - Click here and see Udacity's Active Discounts, Deals, and Promo Codes.
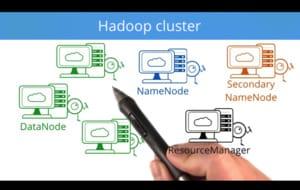
Spark is a top open source project used by the largest companies and startups around the world to efficiently analyze messy data sets.
What You Will Learn
Lesson 1
The Power of Spark
Understand the big data ecosystem
Understand when to use Spark and when not to use it
Lesson 2
Data Wrangling with Spark
Manipulate data with SparkSQL and Spark Dataframes
Use Spark for wrangling massive datasets
Lesson 3
Debugging and Optimization
Troubleshoot common errors and optimize their code using the Spark WebUI
Lesson 4
Machine Learning with Spark
Use Spark’s Machine Learning Library to train machine learning models at scale